Comment bâtir des bases de données sûres et rapides

Un service sensible exige une base de données qui ne flanche pas, ni sur la vitesse ni sur la sécurité. Les spécialistes notent que les mêmes recettes qui protègent une banque servent aussi une plateforme de divertissement : par exemple, des sites de jeux réputés, à l’image de ile casino, reposent sur des moteurs SQL robustes, une segmentation stricte des droits et une observabilité méticuleuse. Entre-temps, l’expérience acquise en développement, en administration SQL Server/MySQL et en cybersécurité fait gagner de précieuses heures, car elle transforme chaque risque en exigence technique traçable. D’ailleurs, une règle simple s’impose : tout ce qui n’est pas explicitement sécurisé finit tôt ou tard par fuir, tout ce qui n’est pas mesuré finit parfois par ralentir, et tout ce qui n’est pas testé finira, un soir de pointe, par surprendre. La pratique montre qu’en traitant la donnée comme un actif, l’architecture, les index et la cryptographie deviennent des alliés naturels. Et, honnêtement, cette rigueur libère ensuite la créativité produit. Parce que rien n’entrave plus une équipe que l’instabilité silencieuse de sa base.
Choisir l’architecture adaptée à des charges critiques
Il faut choisir une architecture qui colle à la charge réelle. Un système orienté transactions requiert un OLTP discipliné, alors qu’un besoin analytique appelle un OLAP bien isolé. Les architectes rappellent que la séparation des préoccupations épargne des nuits blanches. Une base opérationnelle doit rester mince, normalisée, capable d’écrire sans trébucher ; un entrepôt doit agréger, croiser, consolider sans déranger le trafic de production. Entre-temps, une passerelle d’ingestion fiable — file de messages, réplicas dédiés, vues matérialisées — fluidifie le flux sans effets de bord. Entre autres, les spécialistes recommandent d’assumer tôt les partitions temporelles, car le temps est souvent la dimension dominante des jeux de données dynamiques. Enfin, la cohérence n’exclut pas la vitesse : on gagne beaucoup avec une normalisation pensée, assortie de dénormalisations localisées et justifiées par la lecture critique.
Concrètement, la topologie doit être lisible en une page. Les experts conseillent de l’exprimer en domaines : comptes et identité, paiements et limites, sessions et événements, contenu et catalogue, risque et conformité. Cette cartographie réduit les liaisons inutiles et éclaire les ACL de bout en bout. D’ailleurs, un schéma qui raconte une histoire simple se corrige plus facilement à chaud. La pratique montre que chaque table doit posséder un rôle, un propriétaire, un contrat de version et un budget de latence. Et pourtant, combien de bases vieillissent faute de cette discipline initiale. Un bon design sait dire non : pas d’agrégats gourmands dans le cœur transactionnel, pas de jointures acrobatiques en heure de pointe, pas de triggers magiques qui masquent une contrainte mal posée.
Le choix des identifiants pèse lourd. Les équipes préfèrent des clés artificielles stables, numériques, parfois monotones pour la localité des pages, avec une vigilance sur la contention des séquences. Les UUID conviennent à la fédération, mais nécessitent une stratégie d’index adaptée pour éviter l’entropie des insertions. Les collègues insistent sur la clarté des limites : ce qui est globalement unique, ce qui ne l’est que par domaine, et ce qui exige une vérification externe. Les décisions ici conditionnent la simplicité des jointures et la qualité des garanties d’unicité. Honnêtement, mieux vaut quelques octets en plus qu’un identifiant composite incompréhensible. Et, entre autres, la réversibilité compte : un identifiant ne doit jamais révéler la logique interne.
Enfin, il faut préparer l’isolement des lectures analytiques. Un replica en lecture, ou mieux, une chaîne d’ingestion vers un lac et un entrepôt, préserve la vivacité de l’OLTP. Les praticiens séparent les volumétries : événements, métriques, journaux d’audit n’appartiennent pas au même moteur que la transaction monétaire. Cette hygiène évite la compétition sur disque, mémoire et verrous. D’ailleurs, cette séparation devient la base d’une observabilité loyale, quand chaque flux est mesuré là où il naît. La cohérence suit naturellement si les contrats de livraison, de latence et de schématisation sont écrits, publiés et contrôlés.
| Décision d’architecture | Recommandation concrète | Pourquoi cela aide |
| OLTP vs OLAP | Isoler OLTP et reporting via replicas/ETL | Évite la concurrence sur verrous et I/O |
| Normalisation | 3NF sur cœur transactionnel | Réduit les anomalies d’écritures |
| Dénormalisation | Vues matérialisées ciblées | Accélère lectures sans alourdir l’OLTP |
| Partitionnement | Par date ou par région métier | Prunes rapides et scans localisés |
| Clés primaires | Entiers monotonement croissants | Localité des pages, insertions stables |
| UUID/fédération | UUID v7 + index adaptés | Moins d’entropie, ordre temporel |
Comment bâtir des bases de données sûres et rapides
Un service sensible exige une base de données qui ne flanche pas, ni sur la vitesse ni sur la sécurité. Les spécialistes notent que les mêmes recettes qui protègent une banque servent aussi une plateforme de divertissement: par exemple, des sites de jeux réputés, à l’image de ile casino, reposent sur des moteurs SQL robustes, une segmentation stricte des droits et une observabilité méticuleuse. Entre-temps, l’expérience acquise en développement, en administration SQL Server/MySQL et en cybersécurité fait gagner de précieuses heures, car elle transforme chaque risque en exigence technique traçable. D’ailleurs, une règle simple s’impose: tout ce qui n’est pas explicitement sécurisé finit tôt ou tard par fuir, tout ce qui n’est pas mesuré finit parfois par ralentir, et tout ce qui n’est pas testé finira, un soir de pointe, par surprendre. La pratique montre qu’en traitant la donnée comme un actif, l’architecture, les index et la cryptographie deviennent des alliés naturels. Et, honnêtement, cette rigueur libère ensuite la créativité produit. Parce que rien n’entrave plus une équipe que l’instabilité silencieuse de sa base.
Choisir l’architecture adaptée à des charges critiques
Il faut choisir une architecture qui colle à la charge réelle. Un système orienté transactions requiert un OLTP discipliné, alors qu’un besoin analytique appelle un OLAP bien isolé. Les architectes rappellent que la séparation des préoccupations épargne des nuits blanches. Une base opérationnelle doit rester mince, normalisée, capable d’écrire sans trébucher; un entrepôt doit agréger, croiser, consolider sans déranger le trafic de production. Entre-temps, une passerelle d’ingestion fiable — file de messages, réplicas dédiés, vues matérialisées — fluidifie le flux sans effets de bord. Entre autres, les spécialistes recommandent d’assumer tôt les partitions temporelles, car le temps est souvent la dimension dominante des jeux de données dynamiques. Enfin, la cohérence n’exclut pas la vitesse: on gagne beaucoup avec une normalisation pensée, assortie de dénormalisations localisées et justifiées par la lecture critique.
Concrètement, la topologie doit être lisible en une page. Les experts conseillent de l’exprimer en domaines: comptes et identité, paiements et limites, sessions et événements, contenu et catalogue, risque et conformité. Cette cartographie réduit les liaisons inutiles et éclaire les ACL de bout en bout. D’ailleurs, un schéma qui raconte une histoire simple se corrige plus facilement à chaud. La pratique montre que chaque table doit posséder un rôle, un propriétaire, un contrat de version et un budget de latence. Et pourtant, combien de bases vieillissent faute de cette discipline initiale. Un bon design sait dire non: pas d’agrégats gourmands dans le cœur transactionnel, pas de jointures acrobatiques en heure de pointe, pas de triggers magiques qui masquent une contrainte mal posée.
Le choix des identifiants pèse lourd. Les équipes préfèrent des clés artificielles stables, numériques, parfois monotones pour la localité des pages, avec une vigilance sur la contention des séquences. Les UUID conviennent à la fédération, mais nécessitent une stratégie d’index adaptée pour éviter l’entropie des insertions. Les collègues insistent sur la clarté des limites: ce qui est globalement unique, ce qui ne l’est que par domaine, et ce qui exige une vérification externe. Les décisions ici conditionnent la simplicité des jointures et la qualité des garanties d’unicité. Honnêtement, mieux vaut quelques octets en plus qu’un identifiant composite incompréhensible. Et, entre autres, la réversibilité compte: un identifiant ne doit jamais révéler la logique interne.
Enfin, il faut préparer l’isolement des lectures analytiques. Un replica en lecture, ou mieux, une chaîne d’ingestion vers un lac et un entrepôt, préserve la vivacité de l’OLTP. Les praticiens séparent les volumétries: événements, métriques, journaux d’audit n’appartiennent pas au même moteur que la transaction monétaire. Cette hygiène évite la compétition sur disque, mémoire et verrous. D’ailleurs, cette séparation devient la base d’une observabilité loyale, quand chaque flux est mesuré là où il naît. La cohérence suit naturellement si les contrats de livraison, de latence et de schématisation sont écrits, publiés et contrôlés.
Sécuriser par défaut: chiffrement, clés et accès
La sécurité doit être activée par défaut. Le chiffrement au repos et en transit est non négociable. Les spécialistes notent que SQL Server TDE, MySQL InnoDB et TLS bien configurés réduisent déjà la surface d’attaque. Entre-temps, une gestion centralisée des secrets via HSM ou coffre-fort limite les fuites triviales. Le principe du moindre privilège n’est pas un slogan: il dicte les schémas de rôles, la rotation des clés et l’isolement réseau. Les collègues rappellent que l’authentification forte et la séparation des tâches bouchent des failles humaines trop fréquentes. D’ailleurs, un chiffrement qui s’audite vaut mieux qu’un chiffrement qu’on espère. Et, honnêtement, l’effort initial paie quand survient un incident, car la preuve de diligence est là, écrite.
Les équipes définissent des domaines de confiance en couches: pare-feu, sous-réseaux privés, proxys d’application, puis l’instance SQL en réseau fermé, enfin des comptes techniques scellés. Une base n’a pas besoin d’Internet. Un service a besoin d’une jonction claire, d’un point d’entrée contrôlé, d’une liste blanche, jamais d’une promesse vague. La pratique montre qu’un tunnel mal réglé anéantit un VPN bien pensé. Entre-temps, l’audit natif de SQL Server et les logs MySQL doivent remonter vers un SIEM, car les traces isolées dorment, et un signal dormant ne prévient personne. Et pourtant, cela reste oublié: pas de quotas sur les logs, pas de rétention, pas d’alertes. Les spécialistes martèlent: sans alerte, la sécurité n’a pas de voix.
La donnée sensible demande des classes. Données d’identité, télémétrie de session, transactions financières, contenu public: chacune mérite une politique de protection et de conservation. L’anonymisation et le masquage dynamique permettent de travailler sans exposer, en préservant l’utilité des jeux de tests. Un SSO bien mené et une MFA cohérente évitent les comptes de service réutilisés. D’ailleurs, la séparation des environnements coupe les ponts: pas de données réelles en préproduction, jamais. Les collègues ajoutent qu’un jeu de données synthétiques soigné vaut de l’or, surtout quand il reflète les distributions réelles sans rien divulguer. Et la documentation devient alors un outil de sécurité, pas une formalité.
Pour ancrer, voici un plan d’action minimal soutenable. Il pose des garde-fous tout en restant praticable en quelques itérations. La progression est mesurable, l’état se voit dans un tableau de bord, et chaque écart déclenche une tâche. Entre-temps, les revues de sécurité quadrimestrielles s’appuient sur des métriques, pas sur des impressions. La pratique montre que cette cadence apaise les équipes et rassure les auditeurs. Et, au fond, c’est la seule façon d’éviter l’érosion silencieuse des bonnes intentions.
- Activer TLS fort côté clients et serveurs de base de données
- Chiffrer au repos via TDE/clé maître gérée en HSM
- Isoler le réseau: pas d’IP publiques, listes blanches strictes
- Mettre en place SSO, MFA et rotation trimestrielle des secrets
- Appliquer le moindre privilège avec des rôles, pas d’utilisateurs partagés
- Journaliser les accès et requêtes sensibles vers un SIEM
- Classer la donnée et appliquer masquage/anonymisation
- Interdire la donnée réelle hors production; jeux synthétiques signés
- Revoir et tester les politiques à cadence fixe avec preuves
Contrôles d’accès fins et traçabilité vérifiable
Des droits fins et des preuves d’accès sont indispensables. RBAC/ABAC et audits complets rendent les accès explicables. Les spécialistes privilégient des rôles applicatifs stables mappés à des schémas de base, plutôt que des comptes SQL dispersés. Une politique «deny-by-default» réduit les surprises en cas d’ajout de table. Entre-temps, les vues sécurisées et les procédures stockées limitent l’exposition directe des colonnes sensibles. D’ailleurs, les étiquettes de sensibilité portées jusque dans les vues aident à maintenir la cohérence des contrôles. La pratique montre que la traçabilité est un antidote à l’oubli, quand l’humain change et que l’équipe grandit. Et, honnêtement, un audit qui se lit en clair simplifie tout.
Le modèle d’habilitation doit survivre aux changements d’équipe. On préfère confier des droits à des groupes externes synchronisés, jamais à des individus. La révocation devient presque automatique quand une personne part. Les contrôles d’accès temporels, qui expirent sans intervention, évitent les sédiments de privilèges. Entre-temps, les administrateurs système n’ont pas nécessairement besoin des données; ils ont besoin d’administration des instances et de sauvegardes chiffrées, nuance critique. Les collègues insistent sur l’usage de comptes éphémères pour les interventions, avec enregistrement des sessions. D’ailleurs, cette discipline protège autant l’utilisateur que la base.
La traçabilité n’est pas qu’une pile de logs. C’est une chaîne de preuves: qui, quand, quoi, pourquoi, quel ticket, quelle approbation. Les journaux doivent survivre aux cycles et être inviolables. Les solutions d’horodatage fiable, de scellés cryptographiques et de stockage WORM alignent technique et juridique. La pratique montre que ces détails empêchent un débat stérile après incident. Entre-temps, les tableaux de bord exposent trois chiffres simples: nombre d’accès exceptionnels, délais d’approbation, occurrences d’échec. Et si ces chiffres montent, l’équipe sait où agir.
Enfin, l’accès à la production n’est pas un droit d’usage. C’est un prêt, court, réversible, sous contrôle. Les spécialistes recommandent des chemins guidés pour consulter, extraire, corriger, avec une empreinte claire. Une procédure scriptée, validée et versionnée vaut mieux qu’un accès manuel permanent. D’ailleurs, on dort mieux quand les habitudes confortables sont remplacées par des portes surveillées. La qualité de service y gagne, paradoxalement, car on ose davantage changer ce qui doit l’être.
Haute disponibilité et reprise sans surprise
Il faut tolérer les pannes. La disponibilité est une propriété d’architecture et de routine. Les praticiens fixent des objectifs RPO/RTO réalistes, puis dessinent des chemins qui les atteignent sans gymnastique en urgence. Entre-temps, une réplication synchrone couvre la continuité la plus exigeante, quand une réplication asynchrone étire la géographie. Les sauvegardes ne suffisent pas: il faut des restaurations répétées, scénarisées, cadencées. D’ailleurs, les commutateurs automatiques exigent des tests en charge, sinon ils trahiront en pleine affluence. La pratique montre qu’un plan de reprise écrit, testé, daté et signé calme tout le monde. Et, honnêtement, personne n’a jamais regretté une répétition générale de sinistre.
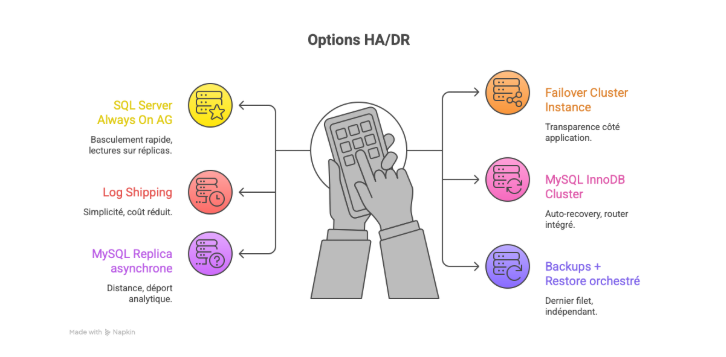
SQL Server et MySQL offrent des chemins variés. Les groupes de disponibilité et les clusters InnoDB proposent résilience et lecture déportée. Le log shipping et les réplicas plus simples gardent une carte B économique. Un proxy de routage des connexions apporte l’élégance d’un basculement fluide côté clients. Entre-temps, les schémas de maintenance — index, statistiques, purge — doivent se répéter de manière coordonnée pour éviter les divergences. Les spécialistes insistent sur la symétrie des nœuds: même version, même configuration, mêmes ressources. D’ailleurs, la différence la plus minuscule devient un piège quand le trafic s’inverse.
Le stockage reste la fondation. Sans profils d’I/O compris et protégés, la promesse HA vacille. Les disques rapides, les groupes de fichiers séparés, les sauvegardes sorties de la grappe évitent la panne en chaîne. La latence de réplique se surveille comme une métrique principale, pas une curiosité. La pratique enseigne de tester avec de vraies tailles: la volumétrie aime la réalité plus que les théories. Entre-temps, l’horloge système et la dérive de temps entre nœuds se corrigent, car la cohérence dépend aussi des secondes. Et l’alerte bruyante prime sur l’alerte silencieuse.
Enfin, chaque plan doit inclure une marche arrière. Un retour en arrière clair et testé limite les pertes lors d’une migration ou d’un patch. Les contrôles préalables — espace disque, état des index, santé des réplicas — forment une check-list rapide, redoutablement efficace. D’ailleurs, les spécialistes gardent une base de secours prête et isolée pour s’entraîner. Le jour où tout va bien, on répète. Le jour où tout vacille, on déroule. La différence, souvent, tient dans ces répétitions.
| Option HA/DR | Avantage clé | Compromis |
| SQL Server Always On AG | Basculement rapide, lectures sur réplicas | Coût et complexité de configuration |
| Failover Cluster Instance | Transparence côté application | Stockage partagé, point de défaillance |
| Log Shipping | Simplicité, coût réduit | RPO plus élevé, basculement manuel |
| MySQL InnoDB Cluster | Auto-recovery, router intégré | Discipline stricte de versions |
| MySQL Replica asynchrone | Distance, déport analytique | Lag possible, cohérence éventuelle |
| Backups + Restore orchestré | Dernier filet, indépendant | RTO long, orchestration nécessaire |
Performance prévisible: index, mémoire et concurrence
La performance se conçoit et se mesure. Des index précis, des statistiques fraîches et des requêtes sobres tiennent la promesse. Les experts commencent par décrire les parcours heureux: lecture par clé, agrégations parcimonieuses, chemins d’exécution stables. Entre-temps, on bannit la paresse des «SELECT *» et on taille les colonnes aux besoins. Les paramètres de mémoire et de cache doivent favoriser les charges réelles, pas hypothétiques. D’ailleurs, la lisibilité des plans d’exécution vaut des pourcentages de CPU. La pratique montre que chaque amélioration de 1 ms répétée des millions de fois paie un loyer énorme. Et, honnêtement, la régularité bat l’éclair de génie épisodique.
Les niveaux d’isolation méritent de l’attention. Le snapshot réduit la contention de lecture, tandis que des écritures longues doivent être fractionnées pour respirer. Les lots transactionnels bornés ménagent le journal et les verrous. Entre-temps, un partitionnement réfléchi transforme un balayage en promenade locale, surtout sur des tables d’événements. Les index composites doivent refléter l’ordre des filtres et des tris dominants; c’est une musique qu’on apprend en écoutant le profilage. D’ailleurs, la suppression d’un index inutile vaut parfois plus que l’ajout d’un index séduisant.
Le cache n’est pas une panacée, mais un amortisseur. Mettre en cache les références immuables et les résultats denses achète du temps aux moteurs SQL. Côté application, un cache TTL court protège contre le phénomène de «thundering herd». Les spécialistes rappellent que la cohérence doit y survivre: invalidations ciblées, clés composées, et surtout pas de cache pour l’état monétaire non idempotent. Entre-temps, le préchauffage au démarrage évite la panique des premiers appels après un déploiement. Et la purge programmée des caches évite les fossiles logiques.
Les plans s’oxydent. Ce qui courait hier trébuche demain, sous une autre distribution. Les équipes surveillent les régressions par canari, par échantillon, par alerte. Un budget de latence par requête critique éclaire les priorités. D’ailleurs, un «query store» bien exploité raconte l’histoire des performances avec dates, versions et cardinalités. La pratique montre que le temps investi à lire ces histoires économise des maintenances héroïques. Et quiconque a vu une pointe de trafic devinerait le reste: la préparation aime les documents vivants.
| Symptôme | Indicateur | Correctif privilégié |
| Lectures lentes | Scans massifs, cache froid | Index ciblé, couverture, préchauffage |
| Écritures bloquées | Verrous longs, journal saturé | Batchs plus petits, isolation snapshot |
| Plans instables | Cardinalités erronées | Stats fraîches, hints mesurés |
| IO en crête | File d’attente disque | Partitionnement, compression, I/O séparés |
| CPU élevé | Fonctions scalaires coûteuses | TVF inline, pré-calculs |
| Contention index | Hot page, séquence unique | Remplacement clé, fillfactor, hash partition |
Prévenir fraude et incohérences transactionnelles
La prévention de fraude repose sur la discipline et la proximité des règles avec les données. Les transactions atomiques et les contrôles de doublon bloquent la plupart des abus triviaux. Les spécialistes rappellent qu’un moteur RNG certifié ne suffit pas ; l’environnement autour doit être infalsifiable et audité. Entre-temps, écrire les règles directement dans la base vaut mieux que disperser la logique dans l’application. D’ailleurs, contraintes d’unicité, soldes calculés côté serveur et idempotency keys forment des remparts simples. La pratique montre que la fraude profite surtout des bords flous de la transaction. Et, honnêtement, ces bords s’épaississent en écrivant les règles au plus près de la donnée.
On verrouille la séquence des événements financiers : réservation, capture, annulation, remboursement. Chaque étape possède son statut, sa preuve et son journal signé. Une table de déduplication avec TTL bloque les replays malicieux. Entre-temps, le plafonnement par utilisateur, appareil, moyen de paiement et intervalle temporel se gère bien en SQL. Les collègues encouragent des jobs anti-corrélation qui détectent vitesses impossibles et croisements suspects de sessions et d’IP. D’ailleurs, un modèle à features clairs, audité, surpasse souvent une boîte noire lorsqu’il faut expliquer une décision.
La détection ne vaut que branchée au temps réel. Les règles chaudes bloquent, les modèles froids instruisent. Un bus d’événements et des vues en flux rapprochent base et algorithme. Entre-temps, la latence d’arbitrage se mesure en percentile, pas en moyenne. La pratique enseigne de déployer de la friction proportionnelle : captcha contextuel, seconde vérification, temporisation ajustée. Trop peu, c’est une porte ouverte ; trop, un mur pour le client légitime. Ce juste milieu s’affine avec les données, pas avec les intuitions seules.
Tout système de jeu honnête aime la contrôlabilité. Joueurs, régulateurs et équipes internes doivent pouvoir retracer un calcul, un gain, une règle. Journaux d’audit signés, empreinte RNG, versions des tables de règles : tout résiste aux contestations. Cette clarté sert la réputation bien plus sûrement que n’importe quel marketing. La confiance s’écrit en lignes vérifiables, et la base de données en garde la mémoire.
Observabilité, tests et automatisation continue
Observer, c’est tenir. Des métriques, traces et logs cohérents rendent la base prévisible. Les spécialistes recommandent peu d’indicateurs fiables, assortis d’objectifs. Entre-temps, des tests de charge répétés après chaque évolution protègent du glissement insidieux. La pratique montre que le chaos, mesuré et borné, renforce les systèmes : une panne simulée chaque semaine apprend au service à tomber debout. L’automatisation des routines de santé libère l’esprit pour les vrais problèmes. Honnêtement, une alerte pertinente vaut plus que cent écrans silencieux.
Les tests unitaires de schéma, procédures et vues détectent l’écart entre intention et réalité. Les tests de migration empêchent le fameux « ça marchait chez moi ». Un pipeline CI/CD spécialisé pour SQL aligne versions, scripts et données de référence. Entre-temps, les semences de données synthétiques rendent chaque test parlant sans divulguer de secrets. Les collègues recommandent un « shadow write » temporaire lors de refontes risquées pour comparer les écarts. Cette prudence accélère paradoxalement le rythme, car elle évite les retours arrière paniqués.
L’observabilité se structure en couches :
- Métriques de base : latences, verrous, I/O
- Métriques métiers : taux d’erreurs, conversions, montants
- Métriques de sécurité : échecs d’authentification, accès exceptionnels
Un corrélateur de traces rattache chaque requête SQL à une session utilisateur. La pratique conseille des SLO explicites : p95 de latence sur requêtes critiques, disponibilité de réplicas, délai de rafraîchissement d’index. Entre-temps, la clarté documentaire écarte le sur-mesure coûteux : on sait ce qui compte et quand alerter.
Automatiser ne veut pas dire abandonner. L’automate escalade, l’humain décide. Rotation programmée des secrets, reconstruction de réplicas, rebasculement test : tout se scénarise. La meilleure documentation est le code lui-même, relu et chronométré. La pratique montre que l’entropie organisationnelle affecte moins les systèmes entretenus ainsi. Cette hygiène permet aux équipes produit, conformité et support de parler une langue partagée.
Indicateurs clés à suivre :
- p95/p99 de latence par requête et par domaine
- Taux de verrous longs et temps moyen de blocage
- Lag de réplique et files d’attente I/O
- Erreurs par cause : logique, réseau, quotas, schéma
- Taux d’échec d’authentification et accès hors horaires
- Volume de journaux d’audit signés et anomalies
- Succès de sauvegardes/restaurations et durée
- Drift de schéma entre nœuds et versions
- Budgets de latence consommés par feature
Gouvernance, conformité et respect des joueurs
La gouvernance protège l’utilisateur et l’équipe. Classer, minimiser, tracer et supprimer à échéance crée un cercle vertueux. Le respect des personnes commence par la sobriété des données collectées. Entre-temps, la conformité stabilise les pratiques et renforce l’architecture. Documentation claire, accès justifiés, rétention bornée : tout inspire confiance. Un registre des traitements lisible redonne du sens à chaque table. La pratique montre que les bases qui savent oublier servent mieux.
Transparence et personnalisation : on peut recommander sans profiler à outrance, en gardant contrôle du grain et des durées. Agrégats anonymes, fenêtres glissantes et segmentations raisonnables suffisent. Entre-temps, un mécanisme d’opposition respecté matérialise le choix des utilisateurs. Les audits de suppression doivent être probants, pas cérémoniels. La cohérence juridique épouse la cohérence technique.
La chaîne KYC/AML s’appuie sur des bases saines : seuils, gels automatiques, revues manuelles s’expriment en règles de données. Un moteur versionné sépare politique et exécution. Les tables doivent se relire comme un texte ; quelqu’un demandera un jour : pourquoi cette décision ce soir-là ? Les spécialistes insistent : la lisibilité est une qualité de sécurité. Contrôles croisés et journaux scellés agissent de concert.
Respect des joueurs = respect des données : pas d’exposition par défaut, pas d’accumulation sans but, suppression à échéance. La confiance devient capital observable : tickets, litiges, rétentions. La pratique montre que cette confiance est portée quotidiennement par une base solide.
Indicateurs de gouvernance :
- Registre des traitements et registre des accès tenus à jour
- Politiques de minimisation et finalités documentées
- Rétentions par classe et expirations automatiques
- Mécanismes d’opposition et d’effacement effectifs
- Moteur de règles KYC/AML versionné et auditable
- Masquage dynamique pour explorations et supports
- Accords de traitement explicites avec sous-traitants
- Preuves de tests de conformité et contrôles croisés
- Communication claire des incidents et remèdes
Données analytiques et personnalisation responsable
Analyser sans déstabiliser : séparer et contracter. Un pipeline ETL/ELT net nourrit un entrepôt sans perturber l’OLTP. Schémas en étoile disciplinés, dimensions maîtrisées, faits atomiques. Un feature store gouverné sert les modèles avec définitions stables. Une métrique doit signifier la même chose partout. La pratique montre qu’une KPI bien définie vaut mieux que dix estimations concurrentes.
Personnalisation : segments sobres, fenêtres glissantes courtes, tests A/B rigoureux, garde-fous activations : plafonds, zones silencieuses, opt-outs. Contrôle humain pour éviter biais. Chaque recommandation laisse une trace explicable : moins d’incidents et de contentieux.
Analytique opérationnelle : SLOs, rafraîchissements ponctuels, latences garanties, mécanismes de rattrapage. Un lot en retard alerte, un schéma en conflit bloque. Gouvernance de schéma pour lacs et entrepôts aussi cruciale que pour OLTP. Cartographie des flux : d’où vient la donnée et qui l’a transformée. Ennemi : ambiguïté sédimentée dans scripts oubliés.
Modèles : décisions sensibles gardent boucle humaine. Seuils = paramètres, pas fatalités. Dérive des données = revues régulières, outillées, comparant intention et résultat. Capacité de simplification = art, et la base de données est l’outil.
Opérations quotidiennes: maintenance, coût et simplicité
Simplicité opérationnelle = vitesse. Fenêtres de maintenance connues, tâches planifiées sobres, versions alignées. Automatiser l’essentiel sans noyer l’équipe. Gestion des coûts : taille des index, rétention des historiques, compression adaptée. Budget stockage affiché = respecté.
Documentation vivante : playbooks, runbooks, check-lists. Une fiche « index en feu » calme 30 % d’un incident. Post-mortems écrits, bienveillants, recherchent le système, pas le coupable. Culture qui améliore base et cohésion.
Versioning : migrations idempotentes, validations préproduction, «dark deploy» avec chemin retour. Outil unique par environnement. Transparence des changements pour équipes aval : moins de quiproquos.
Choisir ses batailles : réplication native, sauvegardes éprouvées, fonctions indexées mesurées. Standard robuste > élégance ésotérique. Objectif : servir vite, garder juste, prouver clair. Le style se juge à la stabilité des nuits.
Conclusion: unir exigence technique et confiance utilisateur
Une base sûre, rapide et vérifiable donne du souffle aux services sensibles. Experts : concevoir proprement, séparer ce qui doit l’être, chiffrer par défaut, mesurer sans relâche, documenter sans emphase. Même rigueur sécurise paiement et plateforme de divertissement.
L’ancre : la donnée comme promesse tenue. Développement, administration SQL Server/MySQL et cybersécurité n’écrasent pas l’expérience utilisateur, elles la rendent fiable. Preuve proche de la ligne d’écriture, métriques claires : bases qui avancent sans vaciller. Quand l’architecture offre ce calme, le produit peut innover, interface juste, sans craindre une alerte oubliée.
